Pengantar R, Pengolahan Data, dan Visualisasi
Selamat Datang!
Pendahuluan
Workshop ini dirancang sebagai sesi live-coding.
- Ikuti praktik secara bertahap sambil mencoba kode sendiri
- Jangan takut bereksperimen dan membuat error kecil
- Target: membangun fondasi dan kepercayaan diri untuk belajar R secara mandiri
Garis Besar Workshop
Workshop ini mengikuti alur kerja data science:
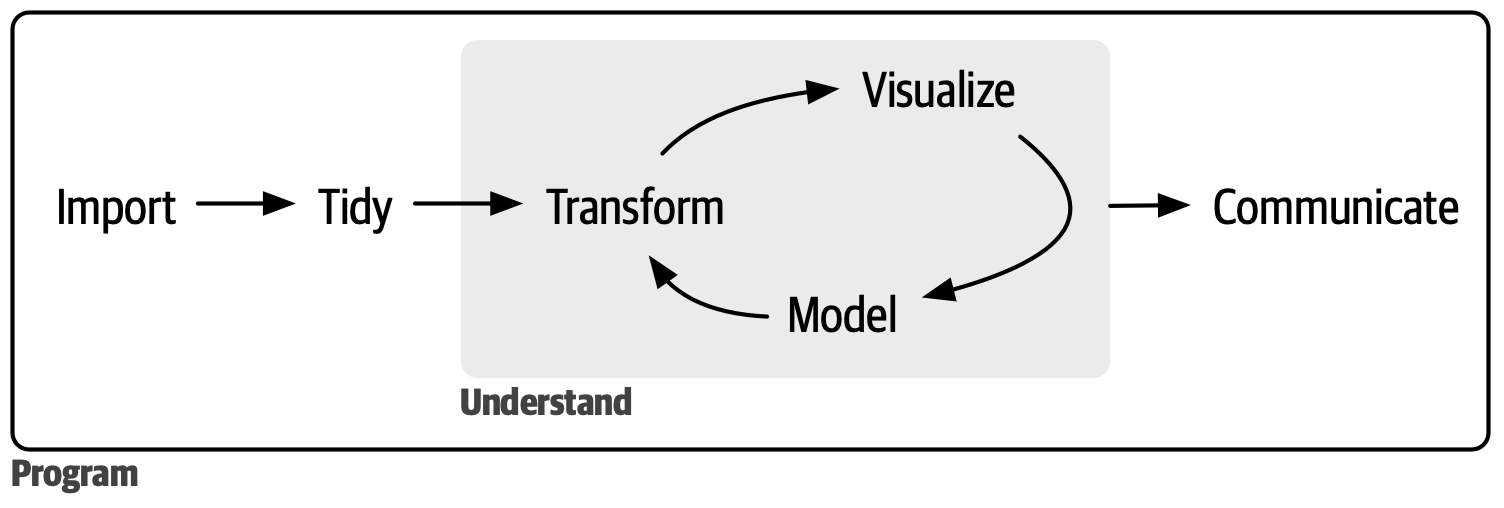
Garis Besar Seri Workshop
- Impor data ke R dari file atau sumber lain
- Rapikan (tidy) data — setiap kolom = variabel, setiap baris = observasi
- Transformasi: filter, membuat variabel baru, menghitung ringkasan
- Visualisasi dan pemodelan untuk memahami pola
- Komunikasikan hasil agar temuan dapat dipahami orang lain
Rencana Hari Ini
Bagian 1: Dasar-Dasar R
- Objek, tipe data, vektor, faktor, dataframe
Bagian 2: Pengolahan Data dengan Tidyverse
- Import, filter, select, mutate, summarize
Bagian 3: Visualisasi dan Statistik Deskriptif
- ggplot2, histogram, boxplot, scatter plot, korelasi
Apa itu R? Apa itu RStudio?
R: Bahasa pemrograman open-source untuk analisis statistik dan visualisasi.
RStudio: IDE yang memudahkan interaksi dengan R — menulis kode, menavigasi file, memeriksa variabel, dan memvisualisasikan plot.
- Instal keduanya: R terlebih dahulu, baru RStudio
- Kunjungi https://posit.co/download/rstudio-desktop
Tur RStudio
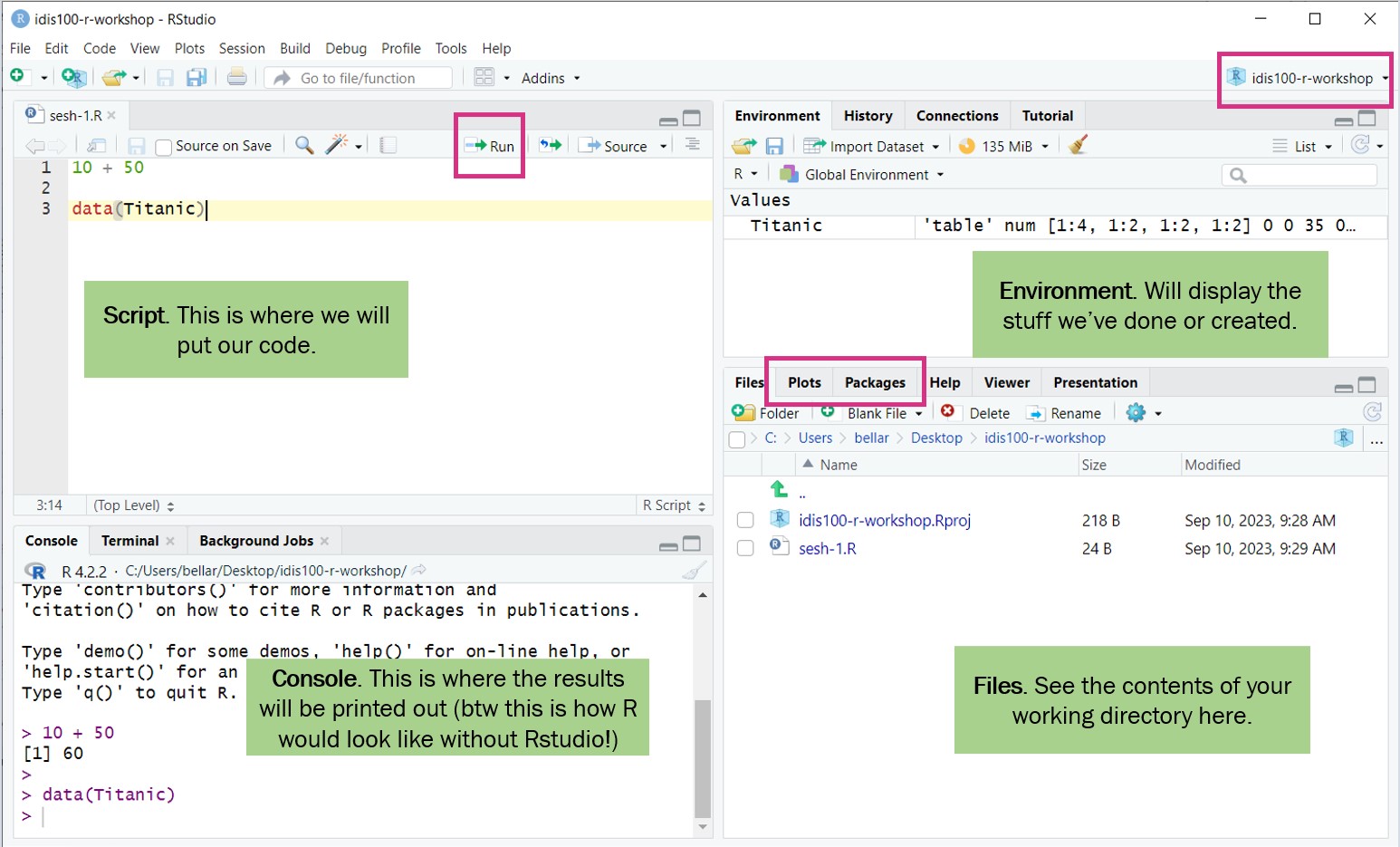
Tampilan R Studio
Sebelum Coding
- Working directory: Gunakan R Project untuk mengorganisir file
- Buat proyek:
File>New Project>New Directory - Buat folder:
data,data-output,fig-output
Tip
Jangan taruh proyek di folder OneDrive. Hindari spasi dan karakter khusus pada nama folder/file.
Mari Mulai Coding!
Buat skrip R baru — File > New File > R script.
Shortcut: Ctrl + Enter (Windows) / Cmd + Return (Mac) untuk mengeksekusi baris kode.
Penyegaran: Tipe Data Kuantitatif
- Nominal/Kategorikal: Data non-urut (contoh: kebangsaan)
- Ordinal: Data berurutan (contoh: peringkat)
- Diskrit: Bilangan bulat (contoh: ukuran sepatu)
- Biner: Dua kemungkinan (contoh: ya/tidak)
- Interval: Tidak ada “nol sejati” (contoh: suhu Celsius)
- Rasio: Ada “nol sejati” (contoh: pendapatan)
Objek dan Nilai di R
"Singapore"adalah sebuah nilai (value)country_nameadalah objek tempat menyimpan nilai<-adalah operator penugasan. Shortcut:Alt+-
Aturan penamaan: tidak boleh dimulai angka, case-sensitive, tidak boleh ada spasi.
Tipe Data di R
Operasi Aritmatika & Boolean
Fungsi di R
Fungsi = resep: menerima input, memproses, menghasilkan output.
[1] 3[1] 3.143.1415926= argumen wajibdigits= argumen opsional- Gunakan
?rounduntuk dokumentasi
Struktur Data di R

- Vektor — beberapa nilai dalam satu objek
- Faktor — variabel kategorikal
- Dataframe — struktur tabular (baris × kolom)
Vektor
[1] 5[1] 7.6Filtering & Menangani NA
Dataframe
country life_satisfaction employment
1 SGP 8 Full time
2 CAN 7 Student
3 NZL 9 Part time
4 SGP 6 Retired
5 CAN 8 Full timeFaktor
Struktur data untuk variabel kategorikal. Memiliki levels.
Mengonversi ke Faktor: Contoh
Nominal:
[1] "Kanada" "Selandia Baru" "Singapura" Ordinal:
[1] "Tidak bekerja" "Pelajar/Mahasiswa" "Ibu rumah tangga"
[4] "Pensiunan" "Paruh waktu" "Penuh waktu"
[7] "Wiraswasta" "Lainnya" Bagian 2: Pengolahan Data dengan Tidyverse
Muat Paket
tidyverse = kumpulan paket untuk data science: dplyr, ggplot2, tidyr, dll.
Mengapa Tidyverse?
Fungsi utama: drop_na(), select(), filter(), mutate(), if_else(), case_when(), summarize()
Import Data
Rows: 13,799
Columns: 16
$ negara <chr> "Kanada", "Kanada", "Kanada", "Kanada", "Kanada…
$ id_responden <dbl> 124070003, 124070004, 124070005, 124070006, 124…
$ pentingnya_keluarga <dbl> 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2,…
$ pentingnya_teman <dbl> 1, 1, 2, 2, 2, 2, 1, 2, 1, 3, 1, 2, 1, 1, 1, 3,…
$ pentingnya_waktu_luang <dbl> 1, 2, 2, 2, 2, 2, 1, 2, 1, 2, 1, 1, 2, 2, 1, 2,…
$ pentingnya_pekerjaan <dbl> 1, 1, 2, 2, 2, 1, 1, 2, 1, 2, 1, 2, 4, 1, 3, 3,…
$ kebebasan_memilih <dbl> 7, 5, 8, 4, 7, 6, 9, 7, 8, 6, 8, 10, 8, 9, 7, 6…
$ kepuasan_hidup <dbl> 5, 8, 9, 7, 1, 7, 9, 6, 7, 6, 7, 10, 8, 10, 6, …
$ kepuasan_finansial <dbl> 8, 2, 8, 8, 9, 8, 9, 5, 6, 9, 5, 7, 9, 9, 7, 8,…
$ religiusitas <dbl> 9, 10, 3, 8, 3, 1, 3, 7, 5, 8, 5, 3, 3, 4, 3, 7…
$ skala_politik <dbl> 10, 5, 2, 8, 6, 6, 7, 5, 6, 4, 5, 4, 1, 7, 2, 8…
$ jenis_kelamin <chr> "Perempuan", "Laki-laki", "Perempuan", "Laki-la…
$ tahun_lahir <dbl> 1944, 1951, 1984, 1975, 1988, 1982, 1981, 1985,…
$ usia <dbl> 76, 69, 35, 45, 32, 38, 38, 34, 65, 31, 27, 33,…
$ status_pernikahan <chr> "Pisah", "Menikah", "Kohabitasi", "Menikah", "B…
$ status_pekerjaan <chr> "Pensiunan", "Pensiunan", "Paruh waktu", "Penuh…Operator Pipe (|>)
Pipe merangkai operasi tanpa variabel perantara. Shortcut: Ctrl+Shift+M.
Data Wrangling: Langkah 1–3
Data Wrangling: Langkah 4–5
Simpan Hasil
Konversi ke Factor
Group By + Summarize
# A tibble: 5 × 4
negara rata_rata sd n
<fct> <dbl> <dbl> <int>
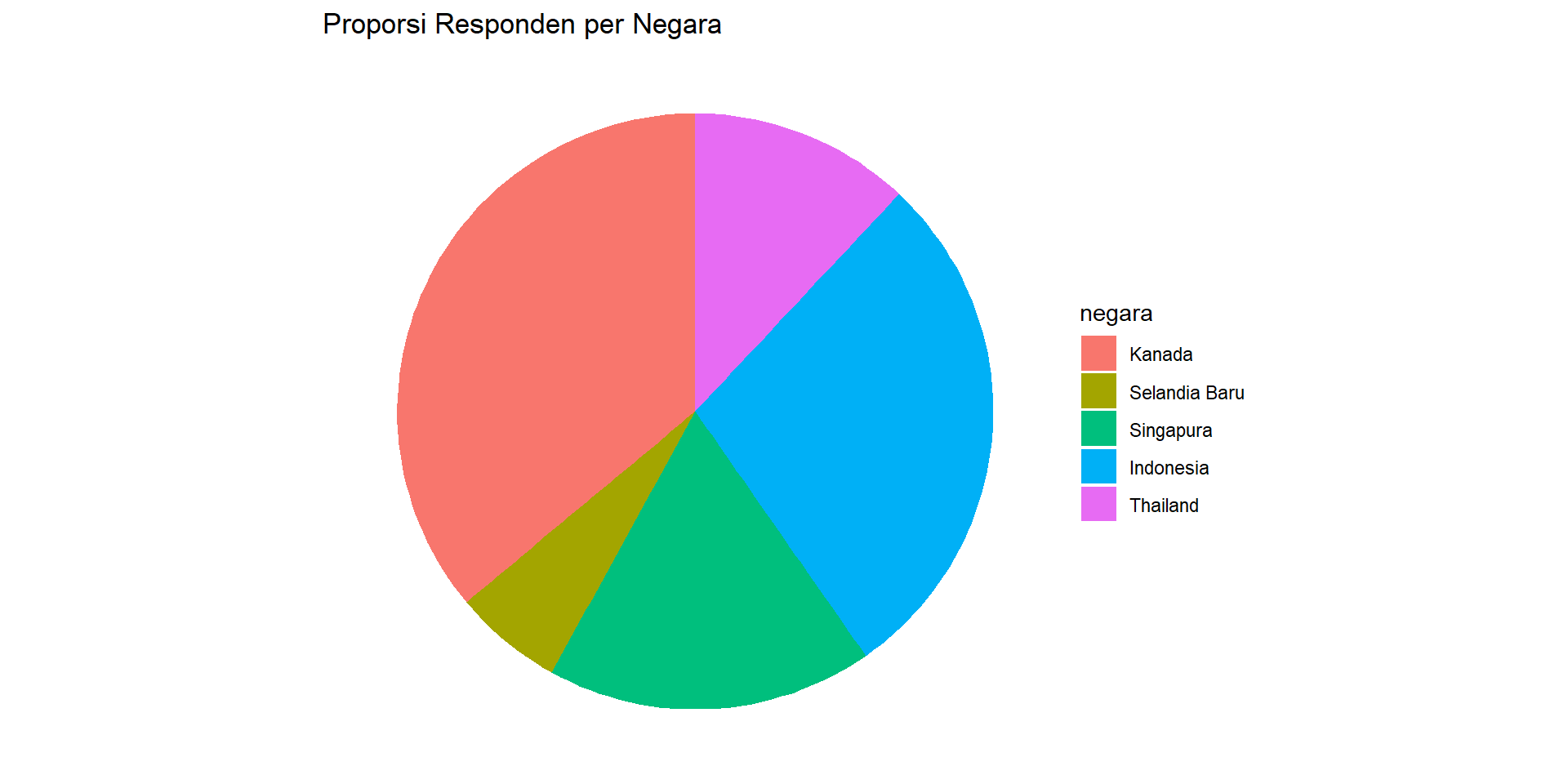
1 Kanada 7.04 1.81 4018
2 Selandia Baru 7.60 1.79 660
3 Singapura 6.99 1.84 1972
4 Indonesia 7.54 2.44 3156
5 Thailand 6.56 2.20 1336Grup Kepuasan: if_else
Di Atas Rata-rata Di Bawah Rata-rata
Kanada 1878 2140
Selandia Baru 423 237
Singapura 824 1148
Indonesia 1850 1306
Thailand 496 840Pivot: Reshape Data
# A tibble: 5 × 5
negara `61+` `45-60` `29-44` `18-28`
<fct> <dbl> <dbl> <dbl> <dbl>
1 Kanada 7.55 6.92 6.99 6.60
2 Selandia Baru 7.96 7.38 7.32 6.70
3 Singapura 7.18 7.01 6.98 6.62
4 Indonesia 7.40 7.46 7.56 7.68
5 Thailand 6.81 6.55 6.53 6.37Latihan Tidyverse
Muat
data/regresi/wvs2.xlsx, gabungkan denganwvs_datamenggunakanbind_rows(). Saring responden Indonesia, hitung rata-ratakepuasan_hidupperjenis_kelamin.
Jawaban
# A tibble: 2 × 3
jenis_kelamin rata_kepuasan n
<chr> <dbl> <int>
1 Laki-laki 7.37 2877
2 Perempuan 7.69 3479Bagian 3: Visualisasi dan Statistik Deskriptif
Statistik Deskriptif: Ukuran Pemusatan
Statistik Deskriptif: Ukuran Penyebaran
Ringkasan per Variabel
# A tibble: 4 × 5
variabel M SD Min Max
<chr> <dbl> <dbl> <dbl> <dbl>
1 kepuasan_hidup 7.15 2.08 -2 10
2 kebebasan_memilih 7.23 2.16 -2 10
3 kepuasan_finansial 6.49 2.36 -2 10
4 usia 45.5 15.9 18 93Pengantar ggplot2
| Komponen | Fungsi |
|---|---|
ggplot() |
Inisialisasi plot dengan data |
aes() |
Pemetaan variabel ke estetika visual |
geom_*() |
Tipe geometri plot |
labs() |
Label dan judul |
facet_wrap() |
Membagi plot berdasarkan kategori |
Histogram
Histogram
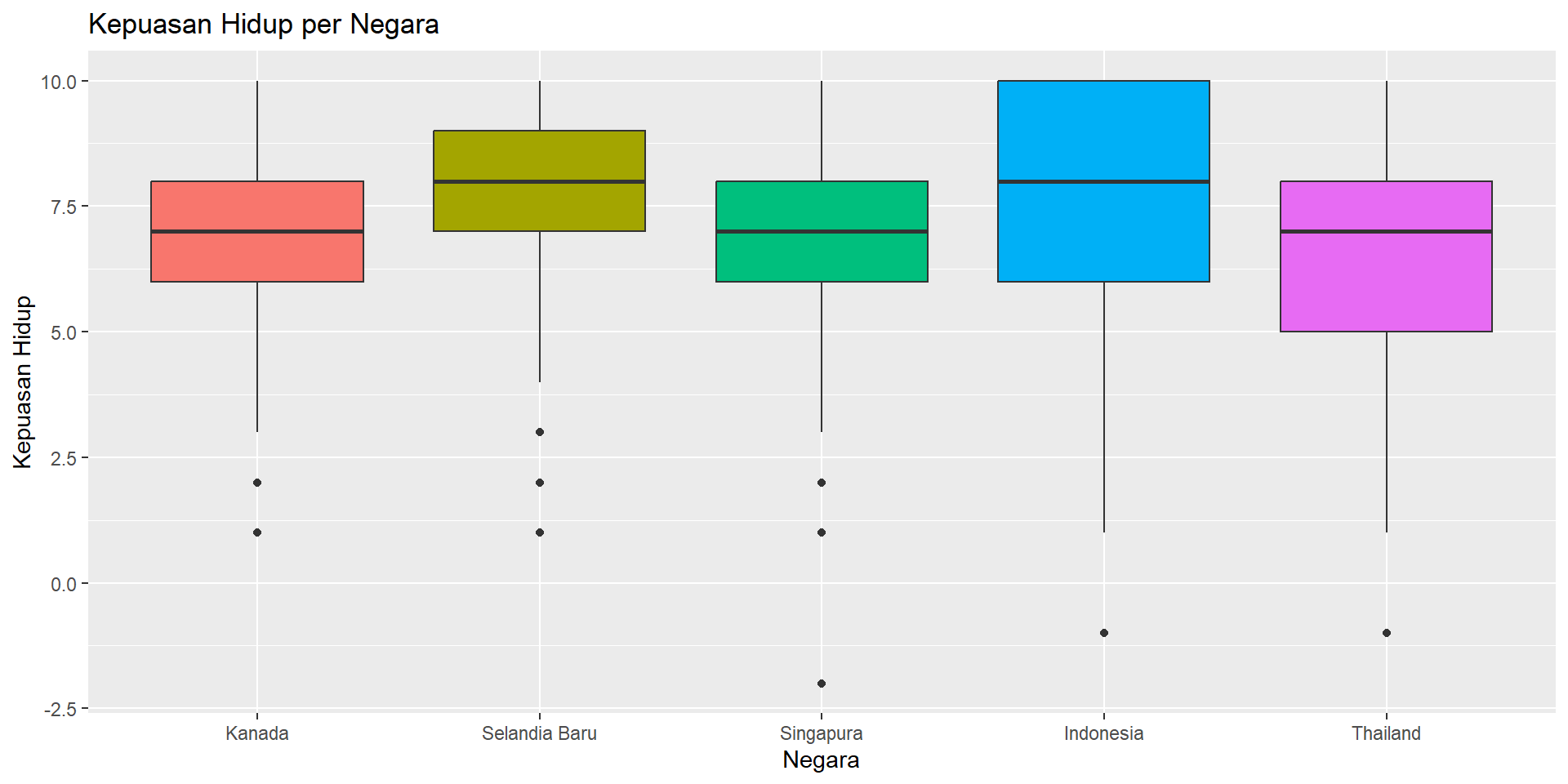
Boxplot per Negara
Boxplot per Negara
Bar Chart
Bar Chart
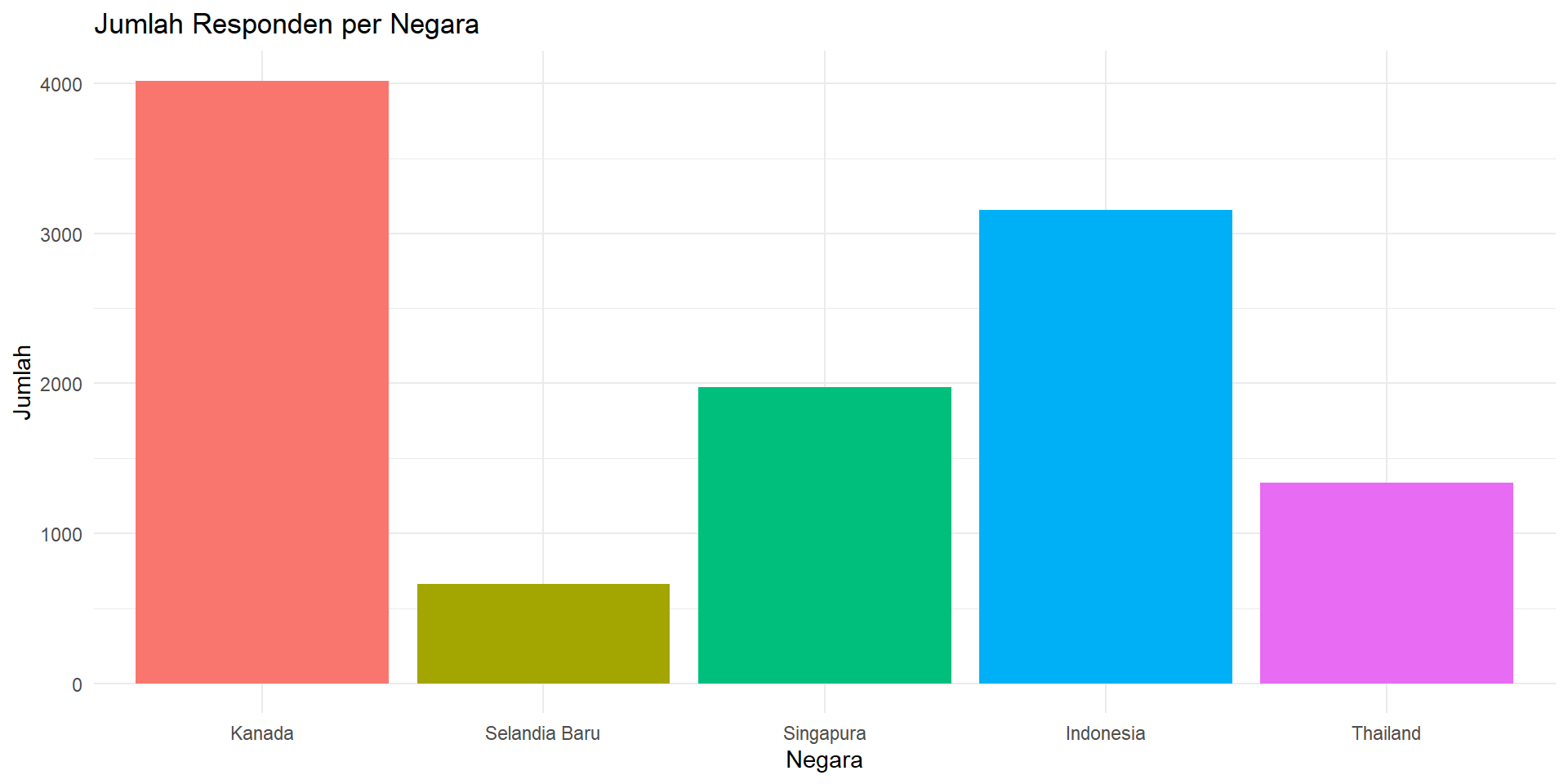
Pie Chart
Pie Chart
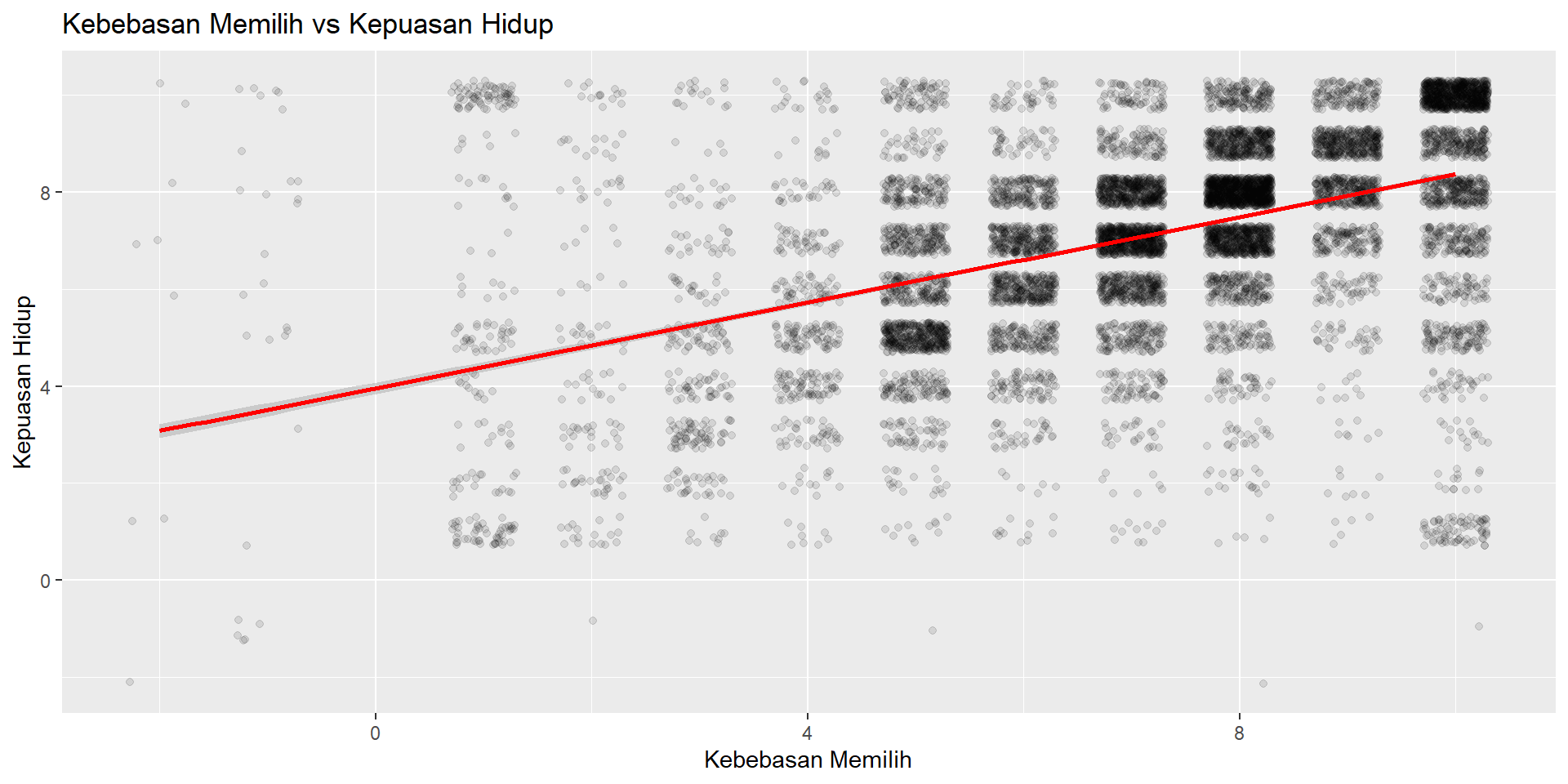
Scatter Plot
Scatter Plot
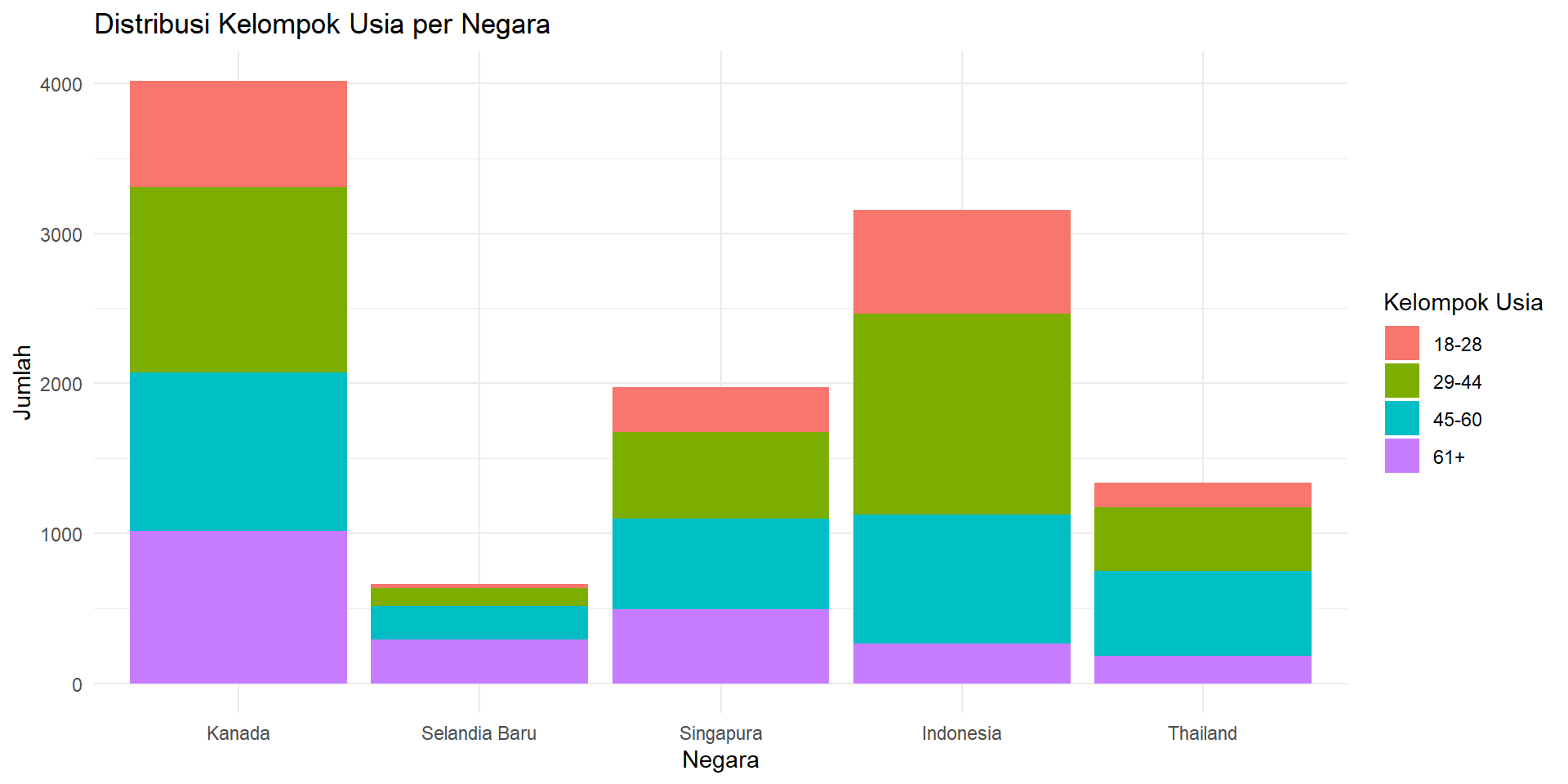
Tabulasi Silang
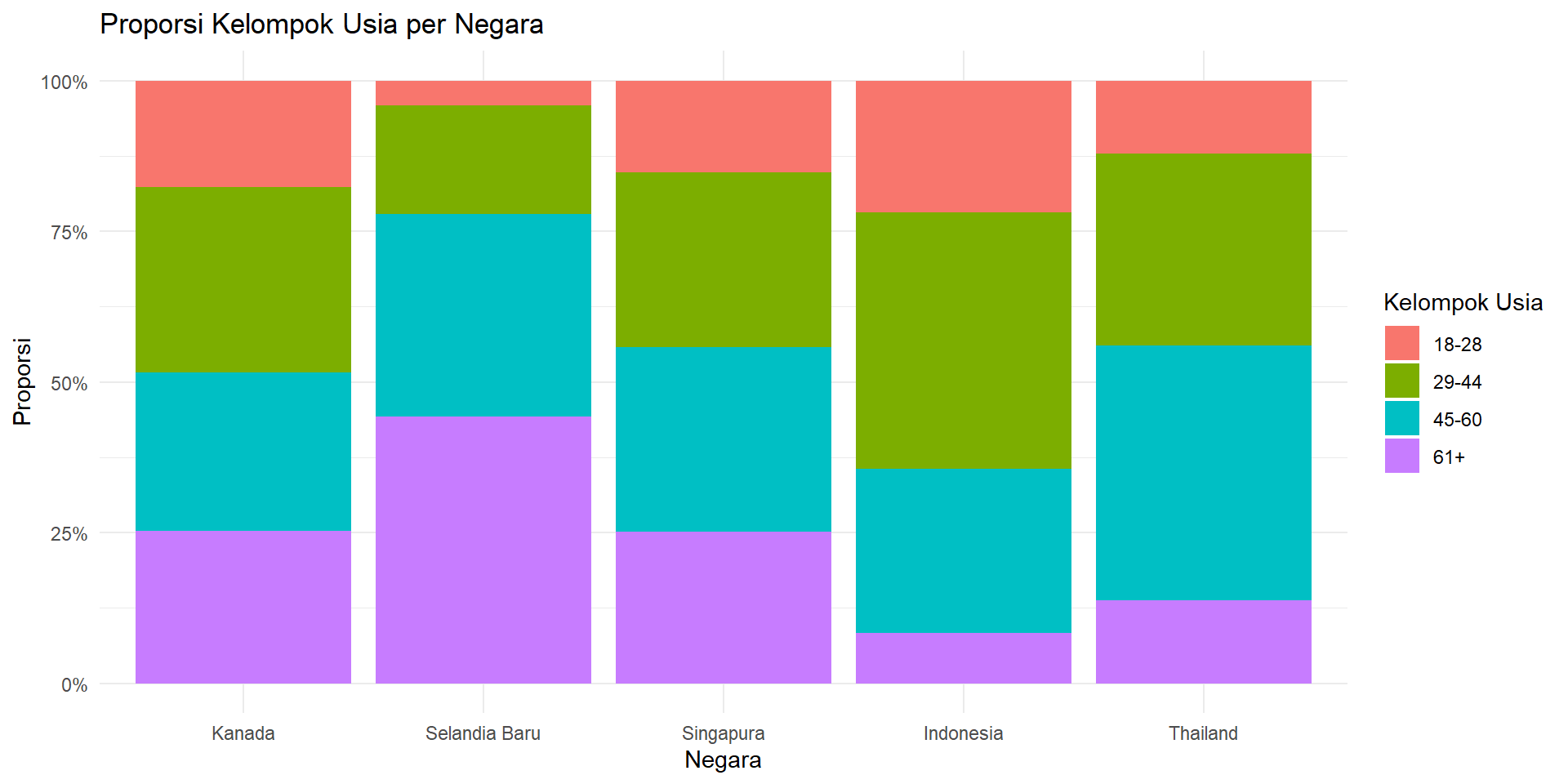
# A tibble: 4 × 6
kelompok_usia Kanada `Selandia Baru` Singapura Indonesia Thailand
<chr> <int> <int> <int> <int> <int>
1 18-28 712 27 299 691 161
2 29-44 1232 119 573 1341 427
3 45-60 1061 222 605 862 565
4 61+ 1013 292 495 262 183Stacked & Grouped Bar Chart
Stacked & Grouped Bar Chart
Proportional Bar Chart
Proportional Bar Chart
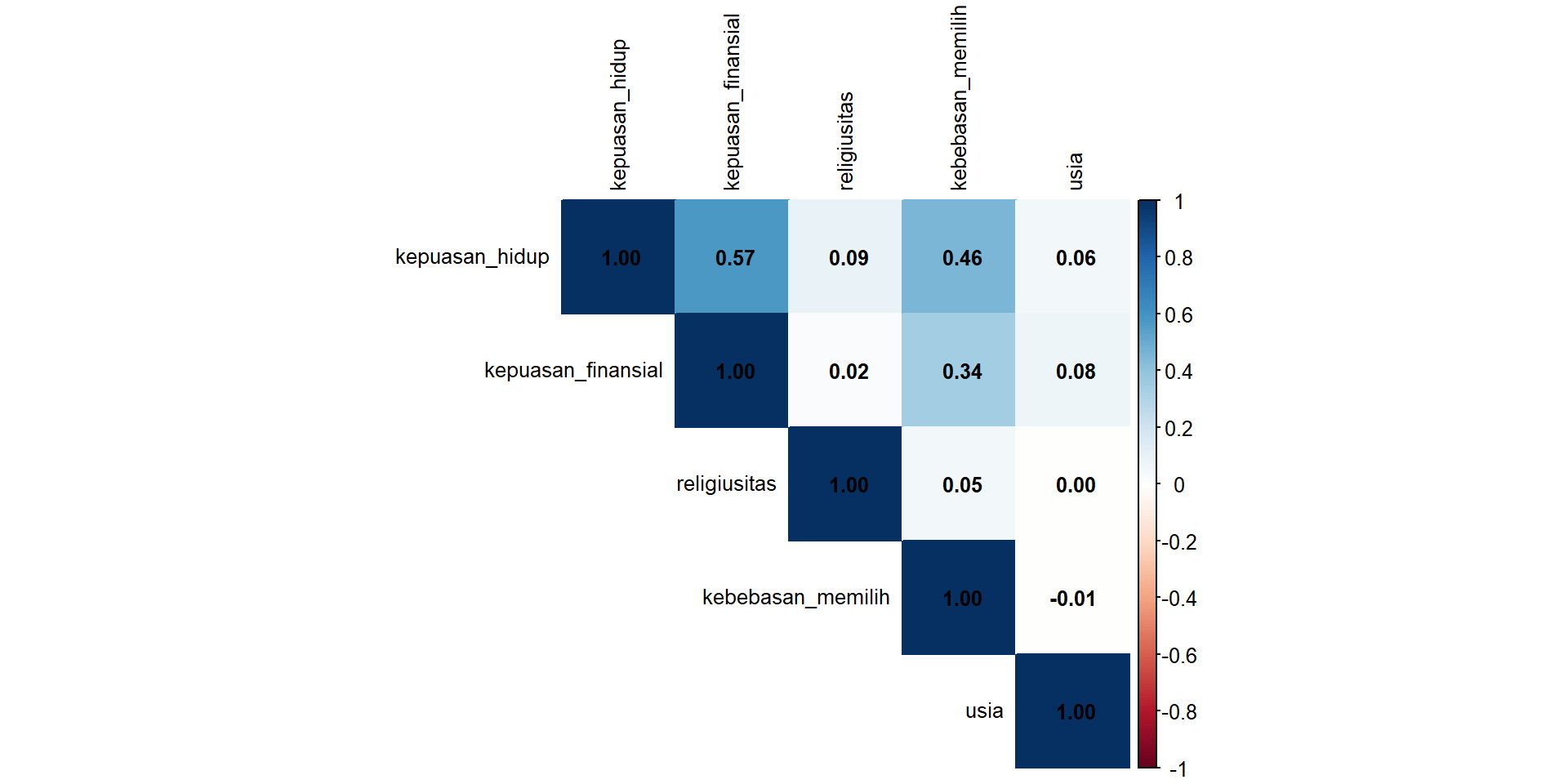
Korelasi
Matriks Korelasi
Matriks Korelasi
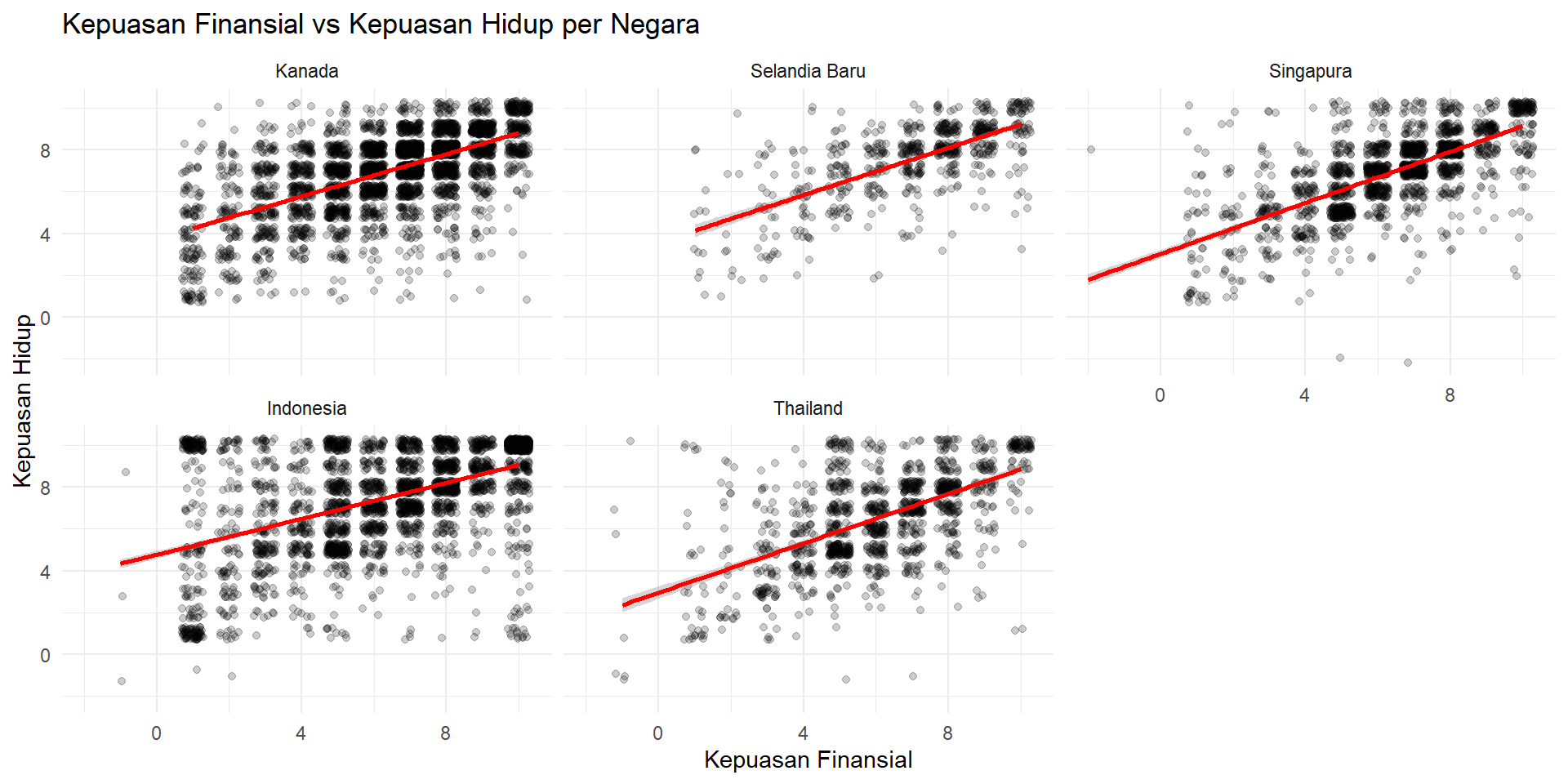
Faceting
ggplot(wvs_cleaned, aes(x = kepuasan_finansial, y = kepuasan_hidup)) +
geom_jitter(alpha = 0.2, width = 0.3, height = 0.3) +
geom_smooth(method = "lm", color = "red") +
facet_wrap(~ negara) +
labs(title = "Kepuasan Finansial vs Kepuasan Hidup per Negara",
x = "Kepuasan Finansial", y = "Kepuasan Hidup") +
theme_minimal()Faceting
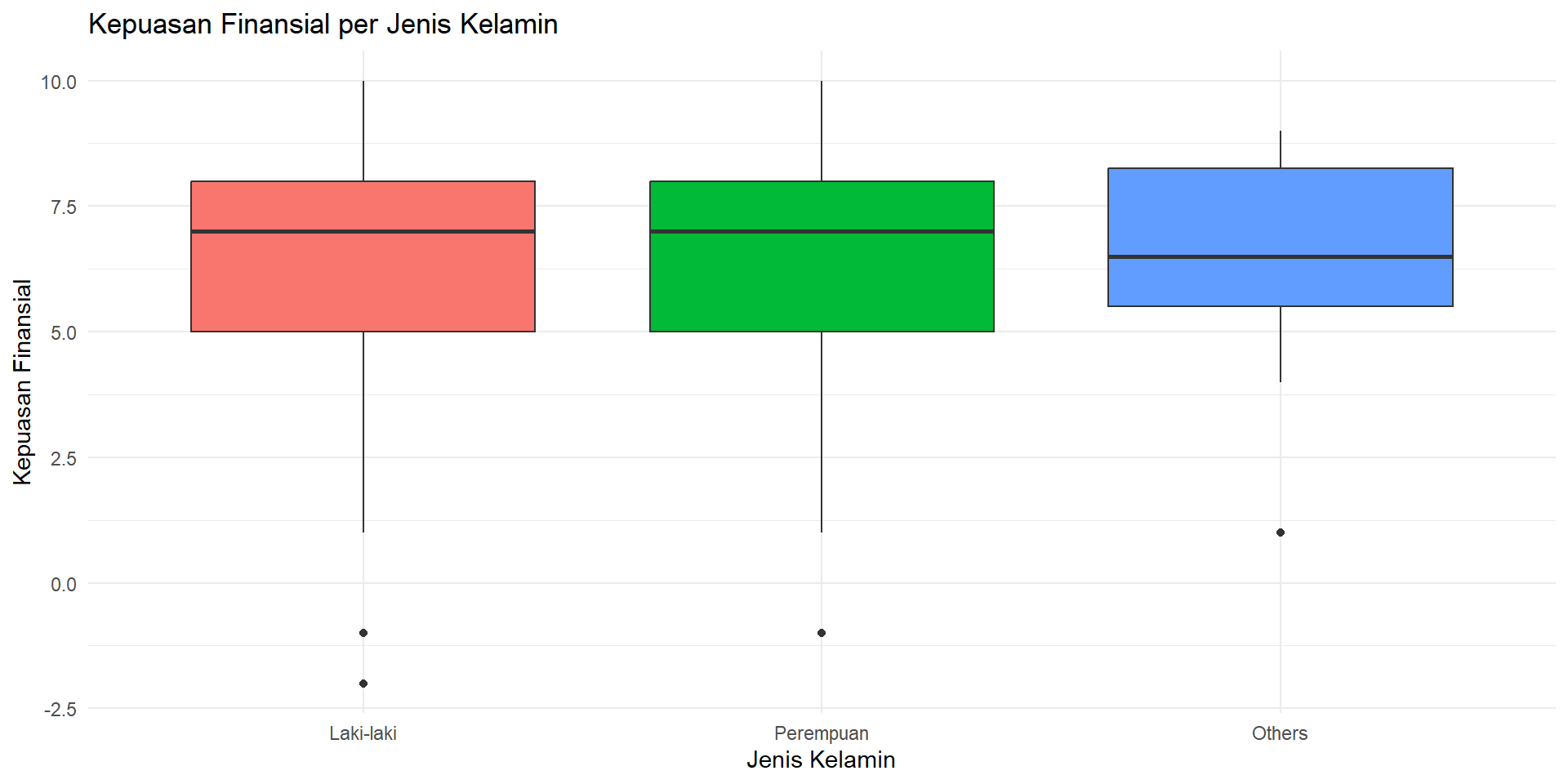
Latihan 1
Buat boxplot
kepuasan_finansialperjenis_kelamin.
Latihan 2
Hitung rata-rata
kebebasan_memilihpernegaradanjenis_kelamin.
Jawaban
# A tibble: 11 × 4
negara jenis_kelamin rata_kebebasan n
<fct> <fct> <dbl> <int>
1 Kanada Laki-laki 7.41 2059
2 Selandia Baru Perempuan 7.74 354
3 Singapura Perempuan 6.86 1059
4 Singapura Laki-laki 6.75 913
5 Kanada Perempuan 7.45 1959
6 Selandia Baru Laki-laki 7.74 306
7 Indonesia Laki-laki 7.66 1431
8 Indonesia Perempuan 7.60 1725
9 Thailand Perempuan 6.16 690
10 Thailand Laki-laki 5.96 638
11 Thailand Others 5.5 8Latihan 3
Buat boxplot
kepuasan_finansialperjenis_kelamin, dengan facet pernegara.
Jawaban
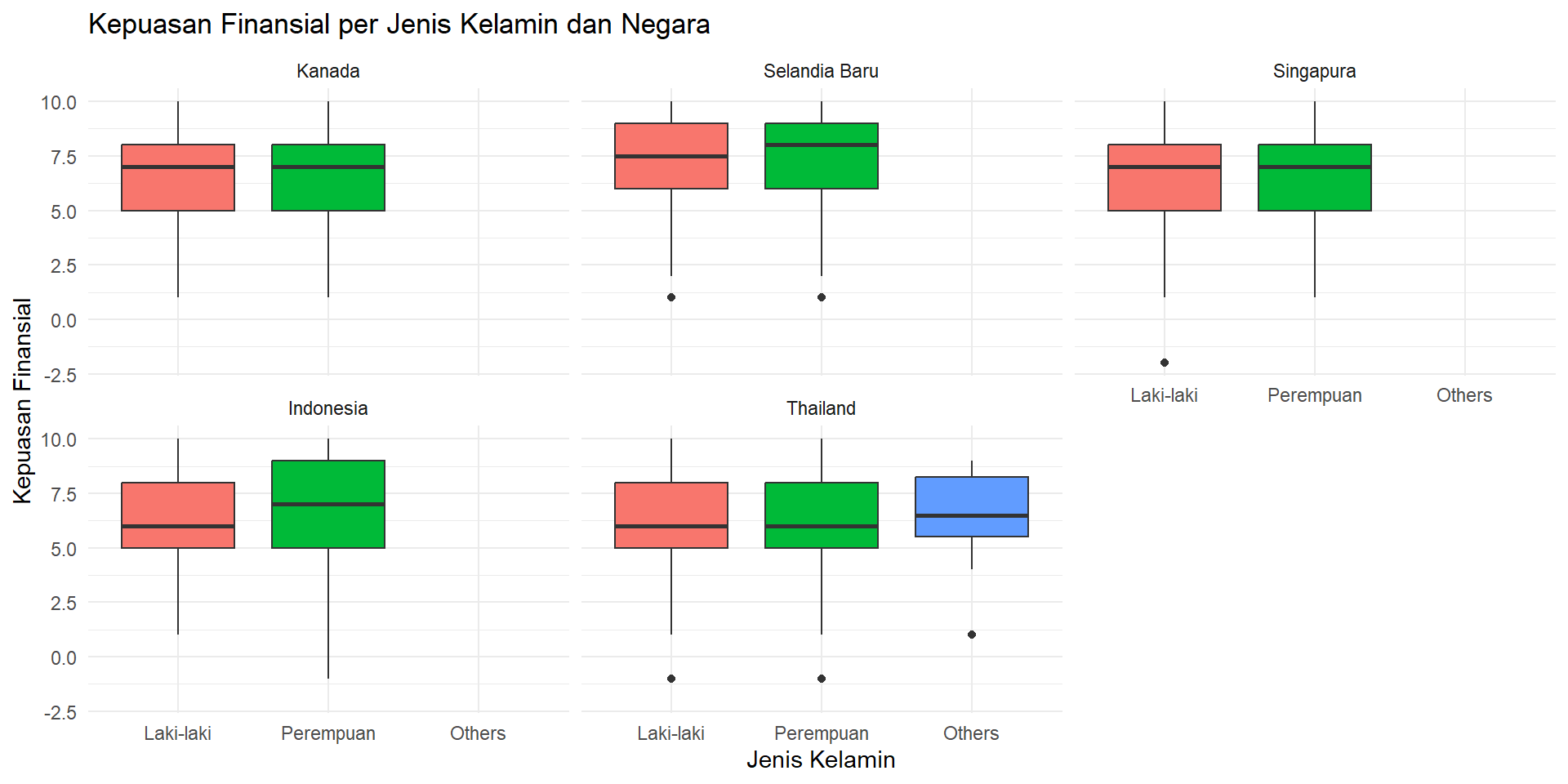
Ringkasan Sesi 1
Apa yang Sudah Kita Pelajari
- Dasar R: objek, tipe data, vektor, faktor, dataframe
- Tidyverse:
select(),filter(),mutate(),case_when(),summarize(),pivot_wider(), pipe|> - Visualisasi: histogram, boxplot, bar chart, pie chart, scatter plot, faceting, korelasi
- Statistik Deskriptif: mean, median, mode, sd, var, range, IQR
Sesi Berikutnya
Sesi 2: Analisis Regresi
- Regresi linear sederhana dan berganda
- Diagnostik dan asumsi
- Variabel kategorikal dan interaksi
Akhir Sesi 1!
Terima kasih! Sampai jumpa di sesi berikutnya.